
This Evolution 101 post is by MSU grad student Tyler Derr
I’m sure you’ve heard the saying that our DNA is the “blueprint” of who we are. Well, our genes are the sequences in our DNA that actually encode instructions for particular functions. What might come as a surprise to some is that in humans over 98% of our DNA is non-coding regions (Elgar and Vavouri 2008). This means that less than 2% of our DNA actually codes for proteins. Pseudogenes, unlike our genes, fit into the non-coding category, but what exactly are they?
A pseudogene is defined as a sequence in our DNA that is homologous to a known gene, but is nonfunctional (i.e. looks like a gene, but for some reason or another, just can’t quite make the cut to creating a functional protein). Therefore it would seem logical to assume, since they can’t make a functional protein, that they serve no purpose. In fact, until just a few years ago, scientists believed that they didn’t have any immediate function. However, now we know that some pseudogenes can actually serve an important function to an organism and not just a critical role in evolution. After discussing the types of pseudogenes and an example of how they can sometimes provide an immediate useful functionality to an organism, we will discuss their relevance to evolution.
There are three main types of duplicated pseudogenes: unitary, duplicated and processed and duplicated non-processed (Figure 1). This categorization is based on how the pseudogenes appear. We shall further discuss these three types below.
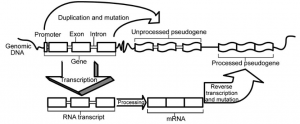
Figure 1: Types of duplicated pseudogenes: unprocessed (top) and processed (bottom). Note that they are all created in some way from a functional gene. Rouchka, Eric C., and I. Elizabeth Cha. “Current trends in pseudogene detection and characterization.” Current Bioinformatics 4.2 (2009): 112-119.
A processed duplicated pseudogene occurs during what is called retrotransposition. This is when a portion of mature mRNA is placed back into the DNA. This type of pseudogene is the easiest to detect in our DNA due to the fact that this process (also known as reverse transcription) allows the insertion of the mRNA poly-A tail into the DNA. The poly-A tail is just a long sequence of ‘A’s, which is a characteristic of mature mRNA and is usually not found in our DNA. One of the reasons why these insertions are classified as pseudogenes is because the placement of the mRNA in the DNA lacks a promoter sequence, which acts as a flag that represents where to start the transcription process. The steps required for making a processed pseudogene can be seen in the bottom section of Figure 1.
The second type of pseudogenes are unprocessed duplicated pseudogenes and are created during the copying of genes in the DNA (gene duplication). Once a gene has been duplicated, if one of the gene copies incurs a mutation, such as a nucleotide change that results in an early stop codon in the middle of the gene, it loses its ability to code for a protein and can be thought of as “junk DNA”. Normally, there would be a huge selection pressure on such a mutation if a single gene no longer functioned, but since the mutation happened on a gene that had undergone gene duplication, there would still be at least one functioning copy of that gene in the genome. Thus, this type of pseudogene can undergo genetic drift and acquire more mutations that have no direct effect on the fitness of the individuals that have this DNA sequence. The duplication and mutation steps are shown in the upper section of Figure 1.
The last type are the same as the duplicated pseudogenes in that they occur due to mutations, but instead of happening to a gene that has undergone gene duplication, unitary pseudogenes are when the mutated gene is the only copy of itself in the genome. The argument used as to why there would not be selection pressure on individuals that have a duplicated pseudogene no longer holds with the unitary pseudogenes. This is because if the mutated gene has no duplicates, then the gene has been completely deactivated.
As mentioned earlier, scientists used to consider pseudogenes in the category of “junk DNA”, nonfunctional gene lookalikes, and knew them mostly as just sequences that caused problems in their studies (e.g. PCR experiments). However, over time and with further study, quite a number of surprisingly interesting findings have been uncovered involving pseudogenes. One specific example from 2010 that was published in Nature discovered that what we had previously known as a pseudogene, PTENP1, was in fact helping suppress tumor growth in many colon cancer cell lines (Poliseno et al. 2010). The basic idea is that although PTENP1 could not undergo translation to become a functional protein, it was able to play the role of a decoy in having microRNA bind with its processed mRNA rather than the mRNA processed from the PTEN gene. This allowed for more PTEN protein since if the microRNA had attached to the PTEN mRNA it would have not been able to undergo translation to becoming a protein. This process is shown below in Figure 2. The authors had proposed that PTENP1 be no longer considered a pseudogene, but instead a “bona fide tumor suppressor gene.”
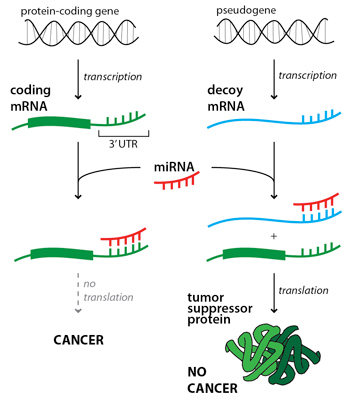
Figure 2: Visual explanation of how the pseudogene PTEN1 can help suppress tumor growth. Image Credit: hms.harvard.edu
Even though we just discussed an example where a pseudogene performs an immediate function for an organism, we also need to mention how they can function beyond the scope of an individual organisms lifetime, and instead on an evolutionary scale. In fact (as mentioned earlier) a duplicated pseudogene has the potential to undergo genetic drift and acquire multiple mutations with no detrimental effects to the fitness of the individual. It can be the case that this sequence of DNA later be resurrected into a gene resulting in a new functional protein being formed (Zhang 2003). It can sometimes be the case that simple (e.g. single nucleotide) mutations can result in huge jumps in the functional space; even to the point where the gene is turned off. It might come as a surprise, but theoretically having multiple mutations (which in comparison results in a larger step in the DNA sequence space) on a duplicated pseudogene can actually result in a smaller step in the functional space. These multiple mutations can result in a fitness improvement to an individual. Thus showing that pseudogenes provide an avenue for genetic drift to take place and due to the resurrection of the mutated duplicated gene an individual can express the a function that provides a fitness improvement.
We have discussed the three main types of pseudogenes, introduced an example that has proven some pseudogenes are actually important in their current state, and discussed reasons as to why they are valuable from an evolutionary standpoint. Although it might not be the case that every pseudogene has a current unique and important function to fulfill, those that currently do not have a purpose are still undergoing genetic drift and could possibly, one day, arise to serve a purpose for our ancestors many years from now.
References:
Elgar, G. and Vavouri, T. (2008). “Tuning in to the signals: noncoding sequence conservation in vertebrate genomes”. Trends in genetics, 24(7), 344-352.
Poliseno, L., et al. (2010). “A coding-independent function of gene and pseudogene mRNAs regulates tumour biology”. Nature, 465(7301), 1033-1038.
Zhang, J. (2003). “Evolution by gene duplication: an update”. Trends in Ecology and Evolution, 18(6), 292-298.
