This post is by MSU PhD Candidate Jinyao Yan.

Jinyao Yan, an MSU BEACON PhD student working in the Statistical Signal Processing Lab, ECE department, but soon to depart to continue her Ph.D. research at the Janelia Research Campus, HHMI.
There are two aspects of biomedical engineering which attract me: the quest for new knowledge, and its power for fostering innovation and promoting society’s development. These pursuits hold my heart; and I am fortunate to follow both passions. Biomedical signal processing appeals to me because it has a mathematical foundation while being transformational in nature. It fuses together my fascination for science and my strong desire to positively influence people’s lives.
During the past half-century, signal processing (SP) has contributed tremendously to 21-st century medical science and practice. Medicine without techniques like magnetic resonance imaging, computed tomography, and ultrasound is almost unimaginable. A rich set of theories and methods are based on linear, time-invariant (LTI) models, and it is these LTI models that have largely supported the spectacular technological change we have witnessed over a few short decades. However, the 21-st century SP engineer is increasingly likely to encounter system analysis and design problems in which LTI models are insufficient. For instance, biomedical systems are complex and are generally nonlinear and time-invariant [1, 2]. The modeling of biomedical systems therefore presents significant challenges not overcome by classical linear methods. In recent decades, intricate research has begun to produce methods for analyzing and modeling isolated classes of nonlinear systems. Biologically-motivated solutions are one extremely compelling current example of this trend. However, this vast class of models still presents many challenges, especially in their application to living systems.
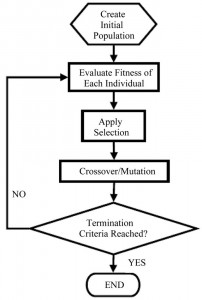
For the last three years, together with my PhD advisors Prof. Erik Goodman and Prof. John Deller, I have worked on evolutionary biomedical signal processing. Our research is concerned with the development of new methods for nonlinear system identification, with broad applicability to modeling problems in biomedicine. The research was initially motivated by the demand for new modeling and evolutionary signal processing strategies for the detection of disease signatures in very low signal-to-noise ratio data [3]. We developed a novel theory and method for nonlinear system identification from measurements under large and complex noise conditions. The approach integrates three modeling and identification strategies: linear-time-invariant-in-parameters (LTIiP) models, set-based parameter identification, and evolutionary algorithms for optimization [4, 5].
Specifically, we treat models as chromosomes: A LTIiP model is the phenotype of a chromosome, a binary sequence in which each bit indicates the presence or absence of a particular gene. Each gene codes for a particular regressor function in the model. A viable model is one with parameter values that allow it to effectively produce the observed output from the observed input. The parameters which appear in the phenotype represent regulators of gene expression, the desired expression being the linear mix of regressors that give the model the highest survival potential. As in nature, survival depends on the inherent suitability of an individual’s genetic makeup to meet the challenges of the environment (reflected in observations), and also in the realization of that genetic potential through an effective parameter set.
The parameter sets result from the set-membership processing of the data. The set-membership algorithms provide sets of feasible parameter vectors rather than a single point estimate. These sets restrict the parameters to those that are possible in light of observations, and they determine the range and statistical viability of the chromosomes.
Following these concepts, the LTIiP model identification problem is formulated into an evolutionary algorithm framework – in particular, a genetic algorithm. The algorithm starts with a random population of chromosomes. Based on the genetic makeup of each chromosome, the feasible set of parameters is deduced using set-membership estimation. Measurable set properties are then used to assign fitness values to each chromosome, and the fitness value is used in the selection process.
Unlike conventional model identification focused on the estimation of parameters, this framework simultaneously addresses selection of the model structure and the parameter estimation. Moreover, a very significant advantage of the algorithm is the lack of need for assumptions about stationarity or distributional characteristics of noise. The ability to identify the correct model with unbiased parameters under complex noise conditions makes the algorithm transformational for practical biomedical data analysis.
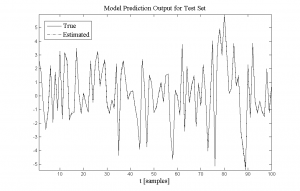
Figure 1: System identification results: True data (continuous curve) and estimated data (dash-dot curve). The identified model shows great tracking ability.
We tested the algorithm on several simulated systems and practical datasets, and it exhibits great tracking performance (Fig. 1). We are now applying the algorithm for identifying nonlinear, effective brain connectivity. Advances in neuroimaging and electrophysiological recording have produced a wealth of image and signal data from different brain regions. One goal is to identify sets of brain regions that are simultaneously involved in the processing of a task. Given that the brain transmission is fundamentally nonlinear at the level of individual cell dynamics [6], exploring if information is encoded in highly-nonlinear ways in the brain is essential.
The dataset we are currently working on consists of electroencephalogram (EEG) data of cognitive control signals (Fig. 2). Much research has shown that our brain responds differently when we make a mistake, and this response is called Error Response Negativity [7]. When a mistake is made, the ACC part of the brain, whose role is seen as monitoring and detecting problems, will send a cognitive control signal to the dlPFC to assign more attention and implement adjustments to address problems. Thus, there is a directional and temporal relationship between the ACC and dlPFC. Some contemporary theories also suggest the cognitive control is nonlinear [8]. The objective is to identify this hypothesized brain information flow using our developed framework.
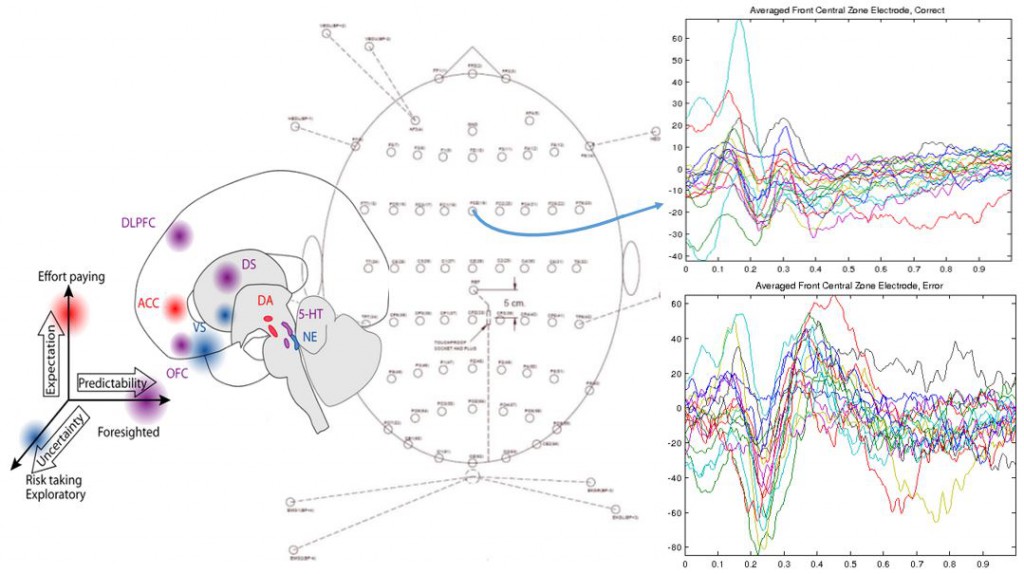
Figure 2: Nonlinear Causal Effective Connectivity Models of the Cognitive Control Networks of the Brain. Left: DLPFC, ACC and related areas of human brain and its cognitive roles (picture credited to https://brmlab.cz/project/brain_hacking/tdcs/pfc). Center: EEG 64 scalp sensors. Upper right: correct response; Lower right: error response.
Besides this application, we are also looking for other applications for neuronal system modeling. Thanks to the great support of my advisers, I am honored to receive a Janelia Graduate Research Fellowship, from the Janelia Research Campus near Washington, D.C. Janelia is part of the Howard Hughes Medical Institute and includes almost 500 scientists pursuing research in fundamental neuroscience and imaging (https://ece.msu.edu/news/jinyao-yan-received-janelia-graduate-research-fellowship). I believe this great opportunity will bring new ideas and possibilities to apply our evolutionary identification methods for biomedical signal processing.
[1] E. R. Dougherty. Translational science: epistemology and the investigative process. Currentgenomics, 10(2):102, 2009.
[2] D. T. Westwick and R. E. Kearney. Identification of nonlinear physiological systems, volume7. John Wiley&Sons, 2003.
[3] B. D. Fleet, J Yan, J. R. Deller Jr., D. Knoester, M Yao, and E. D. Goodman. Breast cancer detection using haralick features of image reconstruction from clinical data of ultra-wideband microwave signals. In Proc. 3rd Work shop on Clinical Image-based Procedures: Translational Research in Medical Imaging (CLIP), 2014.
[4] J. Yan, J. R. Deller Jr., M. Yao, and E. D. Goodman. Evolutionary model selection for identification of nonlinear parametric systems. In Proc. 2014 IEEE China Summit and International Conf. Signal and Information Processing, pages693–697, 2014.
[5] J. Yan and J. R. Deller, Jr., NARMAX Model Identification Using a Set-theoretic Evolutionary Approach, Signal Processing, An International Journal of, Elsevier, 2015.
[6] Hodgkin, A. L., & Huxley, A. F. (1952). A quantitative description of membrane current and its application to conduction and excitation in nerve. The Journal of physiology, 117(4), 500.
[7] J. S. Moser, H. S. Shroder, C. Heeter, T. P. Moran, and Y. Lee. Mind your errors evidence for a neural mechanism linking growth mind-set to adaptive posterior adjustments. Psychological Sciene, page 0956797611419520, 2011.
[8] Y. Liu and S. Aviyente. Quantification of effective connectivity in the brain using a measure of directed information. Computational and Mathematical Methods in Medicine, 2012.




 I spent February 12-17 in Phoenix at the 30th AAAI Conference on Artificial Intelligence.
I spent February 12-17 in Phoenix at the 30th AAAI Conference on Artificial Intelligence.