
This week’s BEACON Researchers at Work blog post is by NC A&T faculty member Scott Harrison.
A practical challenge in genomic studies has been for students to conceive of different outcomes concerning variation, and to test these outcomes against data sets that can contain hundreds of genomes and millions of encoded features such as open reading frames (ORFs). Workflows are contexts of software usage that rely upon frequent interactions with a human operator. As students learn to develop and utilize workflows for genomic analyses, they are building essential skills as 21st century knowledge professionals who will be in-demand for the decision-making and expert knowledge required by these workflows. This is an area of effort I suggest be called “workflowmics.”
Many of the biotechnologies and software tools for genomic data capture and analysis that we utilize today will be radically different in a few years’ time. Perhaps some essential databases and software tools will be maintained and updated, but many will not. Even for those computational resources that remain in demand, changing versions of these resources, underlying programming languages, library dependencies, and host operating systems can dramatically alter the stability and features of an expected software inventory. The meaning of data collected across different data formats, data annotations, protocols and personnel will further challenge how evolutionary biologists aspire to integrate data for the purpose of comparisons across life’s diversity.
Some research in computer science on syntactic and semantic resolution may be expected to guide the development of transformative or “disruptive” technologies, and that is an area worth tracking for anyone with an interest in integrative biological disciplines such as evolution. There are however a wide range of existing computational solutions that are proven and reliable. Even the seemingly trivial usage of a spreadsheet can be very effective at syntactic and semantic resolution, and a spreadsheet application is a classic instance of a software tool relied upon for many workflows. A well-constructed workflow prioritizes a robust mode of implementation and validation by the human operator who will have the flexibility to make various on-the-spot decisions, including those syntactic and semantic resolutions that may not have been anticipated in advance.
Within the context of genomic analysis workflows and their human operators, I am interested to address the following two questions. How will scientific advancement, biotechnological power, and industrial competitiveness follow an efficient path? How do we involve “students” (which, in the fast-paced scenario of data-driven biology, means most everyone) in scientific findings, technical solutions, and industrial productivity? My proposed answer is that an efficient path for genomic studies will come from building knowledge of evolution in a student-centered, diverse community. Similar to how many mechanisms of physical systems can be modeled with several laws of motion, the extraordinary scale of genomic data used to chart life’s diversity can be modeled with several evolutionary processes. There is far-reaching potential for the known evolutionary processes of variation, selection and inheritance to be used across contexts of discovery, experimentation, and engineering. In order to reach this potential, there must be an effective approach for data management. Workflows have been necessary to harness the analytical power of huge volumes of empirical data that can be produced with modern biotechnologies, but a limiting factor has been the large amounts of focused time needed for thorough data analysis. A possible remedy would be “crowd-sourcing.” This requires the recruitment and development of a broad wave of scholars who can be the “mortar between the bricks” – a concept and phrase put forward by Judi Brown Clarke at MSU during a BEACON seminar (October 28, 2011).

An inspirational haiku by the blogger.
Enriched interactions with data sets and software help humans to evaluate small-scale and large-scale aspects of biological systems. In my work as a computational biologist, I am interested to know how studying the scalability of biological systems relates to the navigation of various dimensions that are cognitive, institutional, and social: from molecules to communities, from the laboratory to the clinic, and the usage of knowledge across disciplines respectively. These dimensions run parallel to the student-centered Swail geometric model of student persistence and achievement which addresses the retaining of minority students in higher education. The Swail geometric model (the blue “Student Experience” triangle in the figure) is student-centered in that it focuses directly on institutional practices and other factors directly impacting the student experience. By comparison, other models of student retention in the literature have not been based upon how the overall classroom and college experience connects with social factors impacting the student as a central entity.
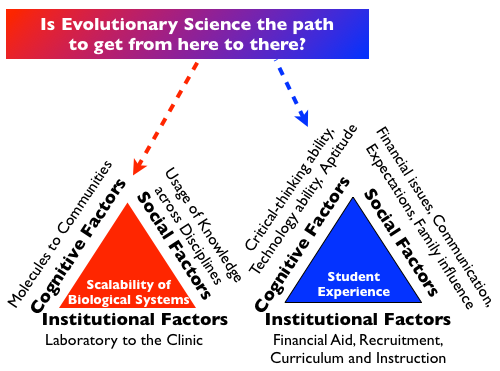
For the red “Scalability of Biological Systems” triangle, cognition may be thought of as arising from a persevering attention to details, along with conceptualizations that are often pluralistic for biological systems. Moving discoveries in the laboratory to the clinic (or from basic science to application) requires a series of institutional commitments, hopefully leading to positive feedback loops involving credit and external funding. In terms of social factors that will breed success, technical ability can accelerate with collaborations that bring knowledge from other disciplines. An effective approach for collaboration was well-expressed in Luis Zaman’s recent essay, http://beacon-center.org/blog/2013/04/11/consultation-is-not-collaboration/. All of these efforts are data-intensive and may be computationally aided. My own laboratory has a mixture of free and commercial genomic analysis software tools, a clinical data management system, and a cadre of students who are conducting data mining efforts for biomedical studies pursued in collaboration with other laboratories.
There is a societal interest in having the outcomes of scientific research connect to industry. For the shift from the red “Scalability of Biological Systems” triangle to the blue “Student Experience” triangle, a $1,000,000 question is about whether knowledge of evolution leads to economic success that is recognized by social factors. Some of what I do to address social factors in my teaching of evolution is to show how it: 1) helps trigger in-depth understanding of complex material previously encountered which will enable students to become “ace” professionals; and 2) guides students in formulating their own original thinking to arrive at new insights and discoveries. For the classroom and laboratory training experiences I have been developing (see Table), the logistical challenges that are being surmounted by students appear to resonate with the standards of competitiveness advocated by leading organizations such as the National Academy of Sciences. As students collect and analyze empirical data to better illuminate life’s complexity, there is abundant opportunity for students to pick up on profe
ssional skills such as experimental design, professional communication, protocol implementation, project management, and interdisciplinary teamwork. I have described some of these classroom and training approaches below.
| Training and Student Experience | Research and Economic Thrust |
| Perl programming workshop on codon usage analysis. Students experience the power of a scripting language for analyzing the textual data of genomics. Analysis of codon usage is a well-studied topic with many hypotheses in the literature. Students assign each other hypotheses to test against recent genomic sequences, and review each other’s work. | Use digital experiments of evolutionary mechanisms in AVIDA to examine costs of alterating a simulated codon set. This work is collaborating with molecular biologists who are experimenting with artificial amino acids being introduced into a modified genetic code. This will expand the repertoire of biochemicals that can be synthesized in vivo for industry. |
| Phylogenetic reconstruction of known evolutionary histories. Students experience the impressive, although imperfect, accuracy of different mathematical models for sequence comparison and tree-building. This initiative is being developed further by hypothesis-driven use of AVIDA, and purification and sequencing of genomic data from the environment. | Pursuit of co-evolutionary studies driven by running next generation sequencing data from environmental samples against multiple reference genomes. This effort has broad applicability to topics in agriculture and complex disease. For a comparative context, the roles of nutrient factors and phenotypes of pathogen-host adaptations are being evaluated. |

Students at North Carolina A&T State University examining phage sequencing data for a phylogenetic reconstruction of a known evolutionary history. This was part of a workshop in the biology department’s undergraduate introduction to research course.
A challenge for all scientific disciplines to consider is whether we are adequately identifying and recruiting students from our nationwide talent pool. The retention and success of minority students in higher education is a key effort of the Department of Biology at my home institution, North Carolina A&T State University, one of the nation’s largest historically black universities. Over the past decade, there have been several recent advances to be credited to many in my biology department. These include increased numbers of students in undergraduate research, increased numbers of students presenting at national conferences, and increased numbers of students moving beyond their baccalaureate training at A&T to earn PhDs. I have been contributing to this effort by helping students directly engage concepts about life’s complexity with real-world data. This can be done through classroom experiences that transition students from classical training approaches in evolutionary science to the usage and generation of powerful software workflows. Successful implementation of complex workflows is essential for STEM careers that must confront a growing range of challenges in interpreting biological data such as complex panels of biomarkers, complex microbial communities, and complex interactions between parasitic and host organisms. Workflow-based training that is both conceptual and experiential will enable academic institutions to deliver upon increased expectations for productivity and competencies from a professionally trained workforce.
For more information, you can contact Scott at scott dot h dot harrison at gmail dot com.
