
This week’s post is by UT Austin graduate student Michael Hammerling.
![]() For as long as I can remember, I’ve been drawn to philosophical questions about the nature of life and its relationship to the physical world. While it became clear to me over time that empiricism and the scientific method are much more powerful tools than pure philosophy for the exploration of such questions, I continue to believe that the most luminary scientists are those who are also philosophers at heart. They challenge paradigms, abhor dogma, and are habitually aware and skeptical of the assumptions that form the basis of their beliefs. A quote credited to Einstein expresses this most concisely: “We cannot solve our problems with the same kind of thinking we used when we created them.” While new, creative ways of thinking are necessary, to scientifically address a problem, we also require technological advances which permit direct empirical testing of hypotheses. Incredible advances in genetic engineering are currently allowing biologists to alter the most fundamental properties of living things, and as a corollary, to question some of our most fundamental assumptions.
For as long as I can remember, I’ve been drawn to philosophical questions about the nature of life and its relationship to the physical world. While it became clear to me over time that empiricism and the scientific method are much more powerful tools than pure philosophy for the exploration of such questions, I continue to believe that the most luminary scientists are those who are also philosophers at heart. They challenge paradigms, abhor dogma, and are habitually aware and skeptical of the assumptions that form the basis of their beliefs. A quote credited to Einstein expresses this most concisely: “We cannot solve our problems with the same kind of thinking we used when we created them.” While new, creative ways of thinking are necessary, to scientifically address a problem, we also require technological advances which permit direct empirical testing of hypotheses. Incredible advances in genetic engineering are currently allowing biologists to alter the most fundamental properties of living things, and as a corollary, to question some of our most fundamental assumptions.
The genetic code is one of the most ancient and revolutionary developments in the history of biological evolution. It describes the rules by which the information contained within sequences of DNA – the primary molecule for storing and passing on genetic information – is translated into the proteins which perform most of the important functions within cells. The rules for translating this code into protein are simple in principle. There are four types of DNA bases, abbreviated A, T, C, and G. In a DNA sequence, every set of three bases is called a codon and has a specified meaning: ATG signifies the START of a protein, three STOP codons (TAG, TAA, and TGA) indicate the end of a protein, and all other codons signify one of the twenty amino acids. The sequence of amino acids in a protein dictates its function. Since there are 64 possible three-base codons but only twenty natural amino acids, the code is redundant, meaning that many of the amino acids may be coded for by more than one codon.
This triplet code is so fundamental to biological life that it is nearly universally conserved in all living things. Since its elucidation, the nature of the genetic code has puzzled some of the greatest minds in molecular biology and evolution. Is it a “frozen accident” of evolution, as Francis Crick proposed, which may have turned out differently if the history of life was replayed, but is now too deeply ingrained in biology to be capable of change? Instead, is the static nature of the genetic code explained because it is in some way optimal, providing the perfect combination of chemical diversity coupled with an ideal robustness against mutation? While the truth likely lies somewhere between these two extremes, the difficulty of engineering changes to the code has prevented the experimental exploration of this topic until now.
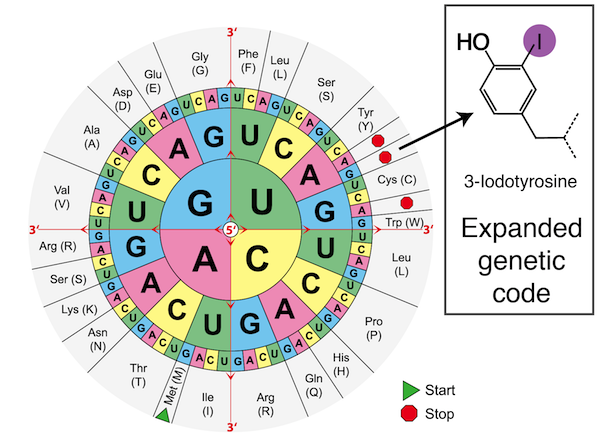
Expanded genetic code. Genetic engineering of the bacterium’s protein translation machinery allows incorporation of a 21st amino acid. By introducing new genetic elements, a codon designates protein termination (STOP) in the natural genetic code now codes for the unnatural amino acid 3-iodotyrosine.
Recent advances in genetic engineering technology have allowed researchers to redefine the meaning of the rarely used amber (TAG) stop codon to specify a large variety of unique 21st amino acids. Many of these amino acids contain interesting chemical groups, and hold great potential for engineering proteins with improved functions. These systems also allow us to ask direct experimental questions about the optimality and flexibility of the genetic code. Will organisms with a newly expanded genetic code evolve to use the new amino acid in their proteins to improve their fitness, or will the new building block be avoided in favor of the canonical set of amino acids? What conditions favor assimilation of the new codon? Will organisms evolved for long periods of time come to require the 21st amino acid for survival? These are the questions I am exploring in my research.
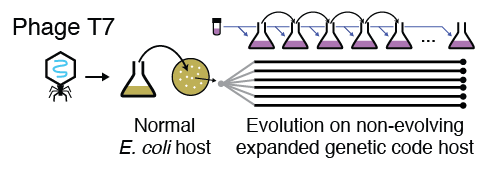
The virus T7 which infects bacteria was allowed to evolve freely for many generations by growing it on a host with an expanded genetic code. The mixed population of viruses that we obtained from this experiment was deep sequenced, with many interesting results.
As a preliminary foray into this area of study, we performed an evolution experiment with T7 bacteriophage, a virus which infects the model bacterium Escherichia coli. This virus has a small genome and grows rapidly, allowing many generations of evolution to be completed in a reasonable amount of time, and yielding interpretable results. It utilizes the host bacterium’s genetic code, allowing us to expand the genetic code of the host to incorporate the unnatural amino acid 3-iodotyrosine at the amber (TAG) codon, and observe the impact on the course of viral evolution. As expected, phage populations evolved to avoid the canonical function of the amber codon as a translation terminator.
In addition, and much to our surprise, multiple phages also evolved to use this unusual amino acid in important and essential genes. In one case, we showed that phages containing the unnatural amino acid in their type II holin protein were more fit than those with the original or any other amino acid at that position, which explained the high frequency this mutation reached in the population. This constitutes the first demonstration of a beneficial mutation enabled by unnatural amino acid incorporation in an organism.
These findings challenge the view of the genetic code as an optimal arrangement, and improve our understanding of one of life’s most basic properties. Under certain conditions, an expanded genetic code can increase the evolvability of organisms and proteins, opening new routes to increased fitness and unique functions. Further work will continue to explore the impact of a variety of unnatural amino acids on the evolution of different organisms and proteins.
For more information about Michael’s work, you can contact him at mhammerling at gmail dot com.
