
This week’s BEACON Researchers at Work blog post is by MSU graduate student Brian Goldman.
 For me, some of the most enjoyable moments in research are when I’m outsmarted by my own creation. Anyone who’s spent enough time with Evolutionary Computing (EC) can probably tell you a story where this happened, but the example I remember learning in my introductory course has always been one of my favorites. Researchers set out to evolve a vacuum cleaning robot. They select whichever robots can “suck up the most dirt.” Seems like a good idea, right? Everything started out okay, with robots cleaning the room decently well. Then one of the robots realized, “If I dump all of my collected dirt on the floor, I can suck it up again!” Sure enough that strategy is very good at sucking up the most dirt, allowing robots to gather more dirt that exists in the room, all without having to move.
For me, some of the most enjoyable moments in research are when I’m outsmarted by my own creation. Anyone who’s spent enough time with Evolutionary Computing (EC) can probably tell you a story where this happened, but the example I remember learning in my introductory course has always been one of my favorites. Researchers set out to evolve a vacuum cleaning robot. They select whichever robots can “suck up the most dirt.” Seems like a good idea, right? Everything started out okay, with robots cleaning the room decently well. Then one of the robots realized, “If I dump all of my collected dirt on the floor, I can suck it up again!” Sure enough that strategy is very good at sucking up the most dirt, allowing robots to gather more dirt that exists in the room, all without having to move.
Maybe that example didn’t really happen, but it illustrates what I do. My research involves deep theoretical and empirical analysis of artificial evolutionary systems, finding negative behavior or unnecessary complexity, and proposing fixes. Just like the faulty robot, many evolutionary systems used to solve real world problems appear straight forward, built using simple rules. Yet the impact of those rules may not be obvious at first glance. Sometimes those degenerate behaviors which hinder optimization can be just as hidden as their causes, meaning the user may not even be aware of the problems they are having.
Over the last year I have focused on Cartesian Genetic Programming (CGP), which is a powerful yet relatively simple way of evolving functions. Some examples of what I mean by functions are circuits, neural networks, robot controllers, image classifiers, and system models (regression). CGP has been used to evolve all of these with great success in the almost 15 years since its inception. For those familiar with genetic programming or other machine learning methods, CGP’s claim to fame is that it can evolve direct acyclic graphs, allowing for intermediate value reuse while still creating relatively comprehensible solutions.
So what degenerate behavior can still exist in such a widely effective and well established evolutionary optimizer? You would think by now all the bugs in a system as simple as CGP would have been found and eliminated. It turns out that there are a number of “features” in CGP which are detrimental to evolving useful solutions quickly that have received little attention or were unknown to the CGP community. The reason they managed to survive this long is that they have been hiding in otherwise beneficial behaviors.
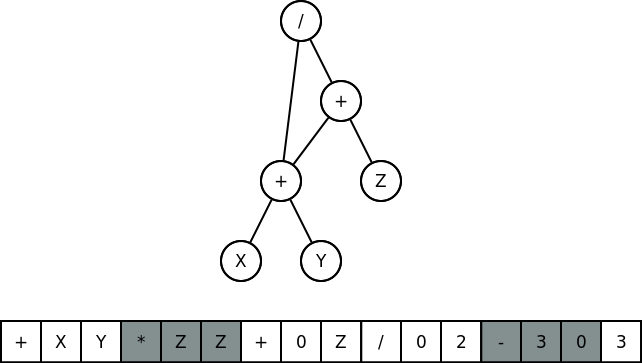
CGP example individual which encodes the function (X+Y) / (X+Y+Z). The top portion is the phenotype and the bottom is the genotype. The grey portions of the genotype are inactive nodes.
It’s time for some concrete examples. The two I’d like to discuss here involve a feature of CGP rarely seen in other EC system: explicitly inactive genes. These are portions of the genome that are identifiably not part of the encoded solution. They may be incorporated in future offspring or may have been used by the individual’s ancestors. In biological terms, these are genes that have no impact on an individual’s phenotype. There is solid theory and a lot of evidence that having these inactive genes is helpful to both evolution in general and CGP’s optimization in specific.
The first behavior I investigated involved the creation of actively identical offspring. What I mean by “actively identical” is that these offspring have no mutations to any of the genes used to encode their solution. They may still have mutations to their inactive genes. These offspring, originally discussed but not investigated by CGP’s creator, have the potential to waste search evaluations. In EC the goal is to obtain high quality solutions using the least number of evaluations, so almost anything that can reduce evaluations improves the algorithm. My contribution was to determine the exact formula behind how much waste was being generated, and to propose three simple ways of modifying CGP to avoid this waste. These techniques improved CGP’s efficiency anywhere from statistically significant amounts to orders of magnitude, depending on configuration. They also made CGP easier to apply to new problems by making search speed less sensitive to the mutation rate, which must be set by the user.
Another touted feature of CGP related to inactive genes is its ability to resist bloat. In the EC community, bloat refers to the tendency for solutions to become more complex with time, with little to no improvement in solution quality. In CGP, evolved solutions almost never approach the maximum size allowed, with most genomes composed almost entirely of inactive nodes. Through probability theory and some tailored test cases I was able to show that CGP’s resistance to bloat was due to a substantial bias in its search mechanisms. I proposed two new techniques which broke free of this bias, improving CGP search efficiency even further as well as reducing solution complexity.
I am currently wrapping up my work with CGP, but I plan to continue performing deep analysis and improvement of evolutionary optimization systems. This fall I plan to propose a few novel systems of my own. For now though its back to white boards, formulas, and paper writing for me.
For more information about Brian’s work, you can contact him at goldma72@msu.edu.
