
This week’s BEACON Researchers at Work blog post is by NC A&T undergraduate Joi Carter and graduate student Henry Williams.
Have you ever read a document that you thought was forged? Perhaps you’ve received an email from your friend, but just knew somehow that they hadn’t actually written it. I know I have read many social media posts that I just knew were the result of a prank and a stolen password and as a student I have been on the receiving end of that prank a couple times. Wouldn’t it be nice if we had a system that could assure you that the proposed author of any text document was actually the author? We can imagine a world where Facebook would automatically remove a status in which I’ve called myself “a pretty little pony,” because it knows the writing style of that post does not match my own and that my account was compromised. This is a topic known as Author Identification.
Author Identification is a process by which an author can be recognized by a sample of text. This process has a history in many fields. Bosch and Smith (1998) worked on categorizing authorship of the Federalist papers and attempting to end a dispute over the 12 papers that several authors claim to have written. In the criminal field a famous use of these techniques can be sighted in the 1996 case against Ted Kaczynski (The Unabomber). The FBI used author identification, and the help of Kaczynski’s family, to prove that he had written the manifesto detailing his plans.

Author Identification is a form of biometric recognition with which many attributes of a person can be gleaned from their writing style, syntax, vocabulary and a nearly limitless list of other potential features. The goal of our work is to determine which potential features are actually useful in this identification process. Many researchers have proposed lists of features that they claim to be salient and have proved to be effective at identifying the authors of a specific type and length of text sample. Our interest in this topic stems from the methodology used by these researchers to test their features. It seems to be a pattern for these researchers to only test their feature sets on a specific type of document. Their test sets contain a limited number of documents which are all nearly identical size and produced by very few authors.
We have been working to find a feature set that can be productive at identifying the author of any possible written piece of text (documents as long as a book or as short as a tweet and even as unusual as programming code). So far we have applied our methods to blog posts and HTML code, both of varying sizes and contexts. Our work involves using Genetic and Evolutionary Feature Selection (GEFeS) along with our proposed Genetic Heuristic Development (GHD) to find these salient features.
The definition of a heuristic is ‘involving or serving as an aid to learning, discovery, or problem-solving by experimental and especially trial-and-error methods’, which is essentially what we have done with our research. We introduced a GHD process which is intended to improve the standard feature selection process. The GHD uses a subset of features produced by GEFeS to create a high performing feature mask for the recognition of unseen subjects. In this case the subset of features produced by the GHD is representative of the most salient style based features for determining the author of a piece of work.
In this experiment, we start with feature selection using GEFeS, as our genetic algorithm of choice. After running feature selection multiple times, we can then produce a heuristic. The development of our heuristic starts with collecting all the best features masks from the validation set produced by GEFeS. We then create a frequency histogram based off this data; each value in the histogram represents the percentage of times that a feature was used by GEFeS in the recognition process.
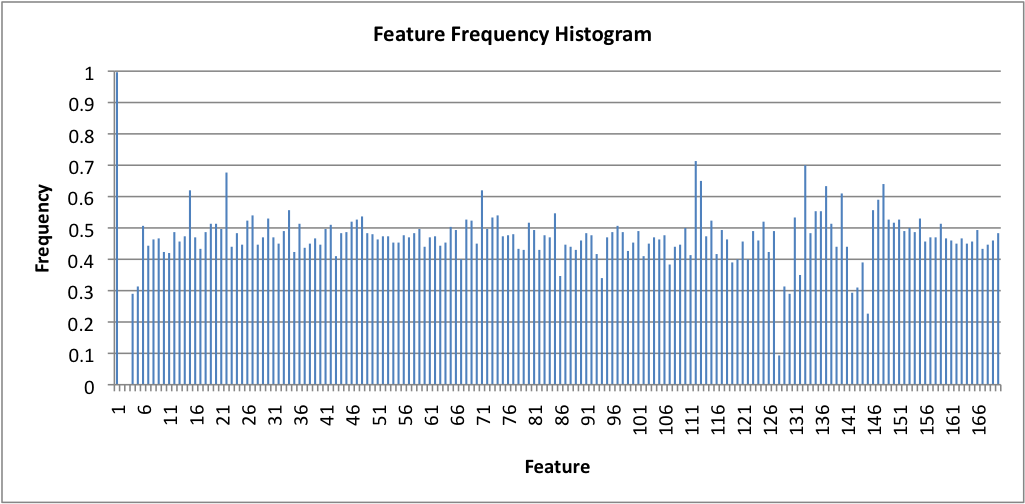
A Feature Frequency Histogram (FFH) can be generated using feature masks found during feature selection. Each value within this FFH represents the percentage of times a single feature was used in all of the best feature masks.
We then test our heuristic at 1% increments for the feature frequency threshold on the validation set to see which subset will give us the best recognition accuracy, i.e. trial-and-error. This experiment resulted in our Genetic Heuristic outperforming the baseline method by doubling the accuracy and by significantly reducing the number of features being used for recognition, which is the goal of any research we conduct in our group. We always aim to successfully increase the recognition accuracy and reduce the number of features required for recognition.
We have a lot more work to do with this research, but that’s the beauty of it. This branch has allowed us to explore things where a lot of people haven’t ventured before which make the possibilities endless in terms of where we can go next. A heuristic can be applied to any feature selection problem; it doesn’t just limit us to Author Identification. It allows us to attempt to pin point which features together are the best, relatively speaking, characteristics for definition. Let’s just say we’ll be very busy for a long while!
For more information about this work, you can contact Joi at jncarte1 at mail dot ncat dot edu or Henry at hwilliams18 at gmail dot com.
